
Variable selection, or specifically wavelength selection, is often a really important intermediate step to develop a good prediction model based on spectroscopic data. If you have been reading these articles this is not news to you: not all wavelength bands have the same predictive power for the primary parameter of interest. It is better therefore to eliminate the bands that are least useful, which often improve the quality and robustness of the model. Today we’ll discuss a band selection method called Backward Variable Selection (or Elimination) and we’ll apply it to PLS regression.
I have discussed a few different flavours of band selection in past articles. You can refer to these posts for some more background information.
- A variable selection method for PLS in Python
- Moving window PLS regression
- Wavelength band selection with simulated annealing
For the topic of today, you can also check a paper by Pierna et al. linked here and cited at the end of this post [1]. The data used for this example are taken from the paper by Ji Wenjun et al. linked here [2], and the associated data is available here.
Backward Selection PLS: a minimal example
The concept underlying Backward Selection PLS is fairly simple.
- Define you model of choice. In this case, PLS regression;
- Define a suitable metric. For this example, RMSE in cross-validation;
- Bin the wavelengths of your data into bands. For the data used here, we start with 210 wavelengths from 310 to 2500 nm. We then bin the wavelengths into groups of 5, ending up with n=42 bands (42×5=210). The importance of this step will become clear as we go.
- Fit a PLS regression model to the binned dataset including all n bands. Calculate the RMSE-CV. This is going to be our baseline to be compared with.
- Loop over the bands. Remove one band at a time and fit a PLS model to the remaining n-1 bands. The band that, once eliminated produces the sharpest decrease in the RMSE-CV, is discarded.
- Repeat the process above with n-1 bands. Loop over them and discard the band that, once eliminated, reduce the RMSE-CV the most.
- Repeat and repeat, iteratively discarding bands, until you reach a point where the RMSE-CV won’t decrease any longer. That is when you stop iterating as you’ve eliminated all bands that are poorly correlated with the quantity you want to predict.
As you can see, we are discarding bands backwards, one at a time, each time getting rid of the worse performing.
OK, let’s see how this works in practice. For clarity, let’s just show the sequence of commands up to the step 5 of the previous list. In essence we want to show how to eliminate just one variable, to avoid the complication of the double loop for the time being.
Let’s begin with the imports
|
1 2 3 4 5 6 7 8 9 10 |
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import LeaveOneOut, cross_val_predict from sklearn.cross_decomposition import PLSRegression from sklearn.metrics import mean_squared_error, r2_score from scipy.signal import savgol_filter from sys import stdout |
Now, let’s load the data, apply a Savitzky–Golay smoothing filter and plot the spectra
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
raw = pd.read_excel("File_S1.xlsx") X = raw.values[1:,14:].astype('float32') y = raw.values[1:,1].astype('float32') wl = np.linspace(350,2500, num=X.shape[1], endpoint=True) X = savgol_filter(X, 11, polyorder = 2,deriv=0) plt.figure(figsize=(12,8)) with plt.style.context(('seaborn')): plt.plot(wl, X.T, linewidth=1) plt.xlabel('Wavelength (nm)', fontsize=20) plt.ylabel('Reflectance', fontsize=20) plt.xticks(fontsize=18) plt.yticks(fontsize=18) plt.show() |

Now it’s time to bin the data into wavelength bands. As anticipated, we’ll define 42 bands, each containing 5 adjacent wavelengths of the original spectra. A neat trick to do with Numpy is to reshape the original array by adding one dimension and then summing over the added dimension.
|
1 2 3 |
# Resample spectra into wavelength bands. Xr = X.reshape(X.shape[0],42,5).sum(axis=2) wlr = wl.reshape(42,5).mean(axis=1) |
Finally, let’s fit a baseline PLS regression model. For this I’m going to use a few utility functions, which are defined at the end of this post. These functions perform basic PLS regression, optimise the number of PLS component to be used in the regression model, and plot the results.
|
1 2 3 4 5 6 7 8 9 10 |
# Find the optimal number of components, up to 20 opt_comp, rmsecv_min = pls_optimise_components(X, y, 20) # Run a simple PLS model with the optimal number of components predicted, r2cv_base, rmscv_base = base_pls_cv(X, y, opt_comp) # Print metrics print("PLS results:") print(" R2: %5.3f, RMSE: %5.3f"%(r2cv_base, rmscv_base)) print(" Number of Latent Variables: "+str(opt_comp)) # Plot result regression_plot(y, predicted, title="Basic PLS", variable = "TOC (g/kg)") |
This code will print the following text
|
1 2 3 |
PLS results: R2: 0.399, RMSE: 5.151 Number of Latent Variables: 9 |
and produce this plot.

That is an OK starting point but there ample room for improving our model. Let’s write a script to perform a single variable elimination and explain it step by step. Let’s start with the code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Define an empty list, to be populated with the RMSE values obtained by eliminating each band in sequance rmscv = [] # Define a Leave-One-Out cross-validator loo = LeaveOneOut() # Loop over the bands one by one for train_wl, test_wl in loo.split(wlr): # Optimise and fit a PLS model with one band removed opt_comp, rmsecv_min = pls_optimise_components(Xr[:,train_wl], y, 10) predicted, r2cv_loo, rmscv_loo = base_pls_cv(Xr[:,train_wl], y, opt_comp) # Append the value of the RMSE to the list rmscv.append(rmscv_loo) # Print a bunch of stuff stdout.write("\r"+str(test_wl)) stdout.write(" ") stdout.write(" %1.3f" %rmscv_loo) stdout.write(" ") stdout.write(" %1.3f" %r2cv_loo) stdout.write(" ") stdout.flush() stdout.write('\n') # List to array rmscv = np.array(rmscv) |
For simplicity, in this example, we are using the entire dataset for this optimisation. In real cases you may want to split your dataset into a training and test set, and perform the optimisation on the training set only.
Anyway, we first define a list to be populated by the RMSE values to be calculated at each step. Then we define a Leave-One-Out (LOO) cross-validator. Note that however, we are not using the LOO cross-validator for cross-validation of the PLS regression. In a normal cross-validation procedure using LOO you would eliminate one measurement at a time (not one band). Unlike that, we use the LOO as a nifty way to iterate over the wavelength bands, discarding one at a time. At each step the variable train_wl is the wavelength band that is eliminated. A model is fitted and cross validated without it, and a RMSE-CV (using standard K-fold cross-validation) is calculated.
At the end of the sequence, which here consists of 42 iterations, we can plot the result along with the baseline RMSE-CV:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
plt.figure(figsize=(12,8)) with plt.style.context(('seaborn')): # Plot the RMSE obtained by eliminating each band plt.plot(rmscv, 'o--', linewidth=2) # Plot the baseline RMSE-CV from the previous step plt.plot([0, 42], [rmscv_base, rmscv_base], 'r', lw=2) plt.xlabel('Index of Band', fontsize=20) plt.ylabel('RMSE-CV', fontsize=20) plt.xticks(fontsize=18) plt.yticks(fontsize=18) plt.show() |
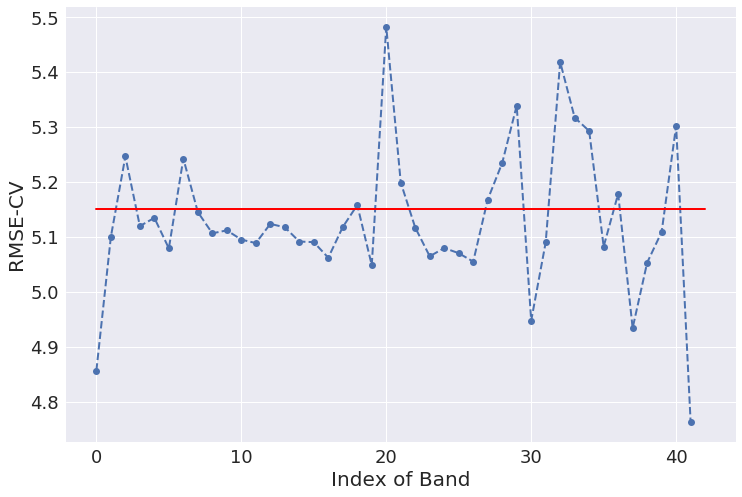
Let’s repeat once again what we have done. First we calculated a PLS model using all bands and estimated the RMSE-CV of such model. That is our baseline (red curve in the chart above). Then we removed one band at a time and each time fitted a new PLS model with the remaining (42-1) bands. For each of these models we estimated the RMSE-CV, which is plotted as blue dots in the graph above.
It’s easy to convince yourself that some of the bands are quite deleterious to the overall model because, once removed, produce a substantial decrease in the RMSE-CV. The the last band, in the instance above, produces the largest improvement once removed. Getting rid of that band would produce an improvement of the RMSE-CV of almost 10%. That is clearly the band we want to eliminate in our bands selection procedure, but we can iterate the process over the remaining band, which is the topic of the next section.
Backward Variable Selection for PLS regression
Now that you understand the basic mechanism, it should be quite easy to iterate over the bands and remove one at a time. The approach used here is to define the arrays to be optimised. One array for the spectra and one for the wavelength bands. Elements will be deleted from these arrays as the optimisation progresses. Let’s call these arrays Xr_optim and wlr_optim with obvious meaning and define them, at the beggining, exactly as we did for the Xr and wlr arrays above. Here’s the full code.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# Resample spectra Xr_optim = X.reshape(X.shape[0],70,3).sum(axis=2) wlr_optim = wl.reshape(70,3).mean(axis=1) rmscv_min = rmscv_base # Initialise to the baseline value iter_max= 70 for rep in range(iter_max): rmscv = [] r2 = [] loo = LeaveOneOut() for train_wl, test_wl in loo.split(wlr_optim): opt_comp, rmsecv_min = pls_optimise_components(Xr_optim[:,train_wl], y, 15) predicted, r2cv_loo, rmscv_loo = base_pls_cv(Xr_optim[:,train_wl], y, opt_comp) rmscv.append(rmscv_loo) r2.append(r2cv_loo) stdout.write("\r"+str(test_wl)) stdout.write(" ") stdout.write(" %1.4f" %rmscv_loo) stdout.write(" ") stdout.write(" %1.4f" %r2cv_loo) stdout.write(" ") stdout.flush() new_rmscv = np.min(np.array(rmscv)) stdout.write('\r') #print(rep, np.argmin(np.array(rmscv)), np.min(np.array(rmscv)), np.array(r2)[np.argmin(np.array(rmscv))] ) print("Rep: %1d, Deleted band: %1d, RMSCV: %1.4f, R^2: %1.4f " \ %(rep,np.argmin(np.array(rmscv)), np.min(np.array(rmscv)),np.array(r2)[np.argmin(np.array(rmscv))]) ) if (new_rmscv < rmscv_min): rmscv_min = new_rmscv Xr_optim = np.delete(Xr_optim, np.argmin(np.array(rmscv)), axis=1) wlr_optim = np.delete(wlr_optim, np.argmin(np.array(rmscv))) else: print("End of optimisation at step ", rep) break |
To track the minimisation of the RMSE-CV, we initialise the relevant variable rmscv_min to the baseline value. For each run of the LOO process we remove one band and calculate the minimum of the RMSE-CV of the new model. If this value is less than the previous we keep going, otherwise the loop is interrupted and the optimisation process comes to an end.
While the optimisation is in progress, this code prints the current index of the band being remove, the RMSE-CV and R^2 of the corresponding model. That is overwritten at each step to avoid filling up the available space (The trick is to use stdout.flush() at the end of each iteration). At the end of one LOO loop a line is printed containing the information on the index of repetition, the band that has been deleted and the best values of the RMSE-CV and R^2 attained at that stage.
Running the code above, I got the following output printed on screen.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
Rep: 0, Deleted band: 0, RMSCV: 4.9201, R^2: 0.4513 Rep: 1, Deleted band: 61, RMSCV: 4.8037, R^2: 0.4770 Rep: 2, Deleted band: 61, RMSCV: 4.7148, R^2: 0.4962 Rep: 3, Deleted band: 4, RMSCV: 4.6644, R^2: 0.5069 Rep: 4, Deleted band: 30, RMSCV: 4.6261, R^2: 0.5149 Rep: 5, Deleted band: 59, RMSCV: 4.5910, R^2: 0.5223 Rep: 6, Deleted band: 56, RMSCV: 4.5448, R^2: 0.5319 Rep: 7, Deleted band: 62, RMSCV: 4.3696, R^2: 0.5672 Rep: 8, Deleted band: 61, RMSCV: 4.2868, R^2: 0.5835 Rep: 9, Deleted band: 56, RMSCV: 4.2194, R^2: 0.5965 Rep: 10, Deleted band: 55, RMSCV: 4.1255, R^2: 0.6143 Rep: 11, Deleted band: 55, RMSCV: 4.0740, R^2: 0.6238 Rep: 12, Deleted band: 53, RMSCV: 4.0400, R^2: 0.6301 Rep: 13, Deleted band: 46, RMSCV: 3.9739, R^2: 0.6421 Rep: 14, Deleted band: 52, RMSCV: 3.9409, R^2: 0.6480 Rep: 15, Deleted band: 15, RMSCV: 3.9181, R^2: 0.6521 Rep: 16, Deleted band: 6, RMSCV: 3.9046, R^2: 0.6545 Rep: 17, Deleted band: 6, RMSCV: 3.8830, R^2: 0.6583 Rep: 18, Deleted band: 18, RMSCV: 3.8761, R^2: 0.6595 Rep: 19, Deleted band: 17, RMSCV: 3.8725, R^2: 0.6601 Rep: 20, Deleted band: 31, RMSCV: 3.8715, R^2: 0.6603 Rep: 21, Deleted band: 8, RMSCV: 3.8710, R^2: 0.6604 Rep: 22, Deleted band: 16, RMSCV: 3.8745, R^2: 0.6598 End of optimisation at step 22 |
The improvement is noticeable. If we now run the regression model with the optimised bands, this is what we obtain.
|
1 2 3 4 5 6 7 |
opt_comp, rmsecv_min = pls_optimise_components(Xr_optim, y, 20) predicted, r2cv_optim, rmscv_optim = base_pls_cv(Xr_optim, y, opt_comp) print("PLS results:") print(" R2: %5.3f, RMSE: %5.3f"%(r2cv_optim, rmscv_optim)) print(" Number of Latent Variables: "+str(opt_comp)) regression_plot(y, predicted, title="Optimised-bands PLS", variable = "TOC (g/kg)") |
|
1 2 3 |
PLS results: R2: 0.660, RMSE: 3.871 Number of Latent Variables: 10 |

Here you go. A minimal code to run your own Backward Variable Selection for PLS Regression. Thanks for reading and until next time,
Daniel
References
- J. Pieran et al., A Backward Variable Selection method for PLS regression (BVSPLS), Analytica Chimica Acta 642, 89-93 (2009).
- J. Wenjun et al., In Situ Measurement of Some Soil Properties in Paddy Soil Using Visible and Near-Infrared Spectroscopy, PLOS ONE 11, e0159785 (2016).
- Featured image credit: Valiphoto.
Python functions used in this post
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
def base_pls_cv(X,y,n_components, return_model=False): # Simple PLS pls_simple = PLSRegression(n_components=n_components) # Fit pls_simple.fit(X, y) # Cross-validation y_cv = cross_val_predict(pls_simple, X, y, cv=10) # Calculate scores score = r2_score(y, y_cv) rmsecv = np.sqrt(mean_squared_error(y, y_cv)) if return_model == False: return(y_cv, score, rmsecv) else: return(y_cv, score, rmsecv, pls_simple) def pls_optimise_components(X, y, npc): rmsecv = np.zeros(npc) for i in range(1,npc+1,1): # Simple PLS pls_simple = PLSRegression(n_components=i) # Fit pls_simple.fit(X, y) # Cross-validation y_cv = cross_val_predict(pls_simple, X, y, cv=10) # Calculate scores score = r2_score(y, y_cv) rmsecv[i-1] = np.sqrt(mean_squared_error(y, y_cv)) # Find the minimum of ther RMSE and its location opt_comp, rmsecv_min = np.argmin(rmsecv), rmsecv[np.argmin(rmsecv)] return (opt_comp+1, rmsecv_min) def regression_plot(y_ref, y_pred, title = None, variable = None): # Regression plot z = np.polyfit(y_ref, y_pred, 1) with plt.style.context(('seaborn')): fig, ax = plt.subplots(figsize=(12, 7)) ax.scatter(y_ref, y_pred, c='red', edgecolors='k') ax.plot(y_ref, z[1]+z[0]*y_ref, c='blue', linewidth=1) ax.plot(y_ref, y_ref, color='green', linewidth=1) if title is not None: plt.title(title, fontsize=20) if variable is not None: plt.xlabel('Measured ' + variable, fontsize=20) plt.ylabel('Predicted ' + variable, fontsize=20) plt.xticks(fontsize=18) plt.yticks(fontsize=18) plt.show() |



